|
|
|
|||||||
 |
|
|
Опции темы |
Рейтинг: 
|
Опции просмотра |
|
|
 10.06.2019, 20:10
10.06.2019, 20:10
|
#1 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
[URL=https://a-parser.com/threads/5395/]1.2.503 - обновление JavaScript движка и множество улучшений[/URL]
 Улучшения
Исправления в связи с изменениями в выдаче
 [/URL] [/URL] |

|

|
|
20.06.2019, 15:06
|
#2 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
Сборник рецептов #33: парсинг Google карт, сбор вопросов из поиска, перевод текстов целиком(https://a-parser.com/threads/5423/)
33-й сборник рецептов, в котором мы будем собирать данные из Google maps в указанной местности, спарсим блок вопросов и ответов в поиске Гугла и научимся использовать файлы целиком в качестве запросов. Поехали! Сбор всех организаций в определенной местности Начиная с версии 1.2.482 в A-Parser появились парсеры карт Google и Яндекс. Принцип работы обоих одинаков - в настройках указываются координаты точки и зум, парсер собирает результаты поиска по ключевым словам в этой точке и области вокруг нее, ограниченной зумом. Но если стоит задача собрать данные, например, со всего города, то для ее решения нужно указывать диапазон координат и "заставить" парсер пройтись по ним. Как это сделать, а также пример пресета - все это показано по ссылке выше. 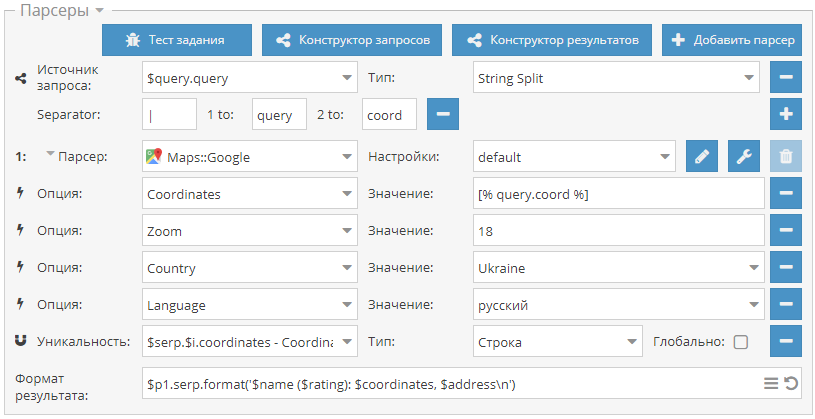 Парсер собирающий вопросы и ответы из выдачи Google Google по некоторым запросам показывает в поисковой выдаче блок вопросов и ответов People also ask (Похожие запросы). Наши пользователи периодически интересуются, как можно парсить этот блок, получая отдельно вопросы и ответы на них. Поэтому мы публикуем в нашем каталоге пример такого парсера, а забрать его можно по ссылке выше.  Использование файлов целиком в качестве запросов\ Общеизвестно, что в А-Парсере каждая строка в исходном файле - это отдельный запрос. Но существуют задачи, когда необходимо использовать все содержимое файла как один запрос, игнорируя разбивку на строки. Благодаря JavaScript парсерам такая возможность есть и по ссылке выше опубликован пример парсера, который получает все содержимое файла, переводит его на заданный язык и сохраняет в новый файл. 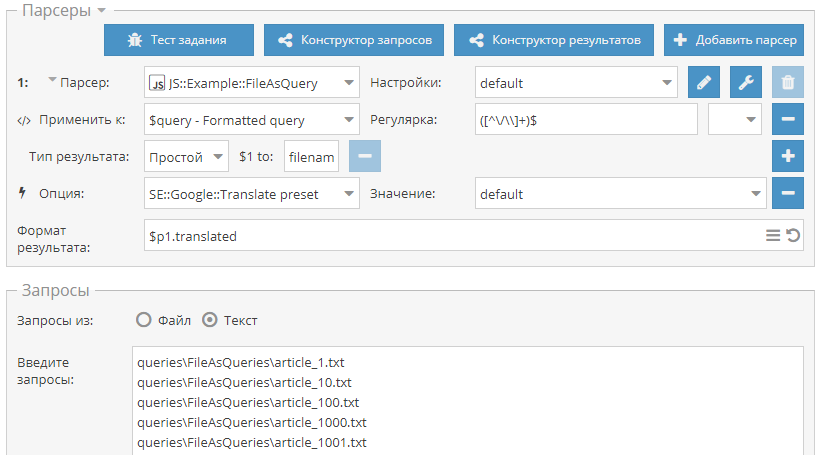 Еще больше различных рецептов в нашем Каталоге(https://a-parser.com/resources/)!  https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ |
|
|
|
|
02.07.2019, 15:35
|
#3 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
Видео урок: Макросы подстановок(https://a-parser.com/threads/5453/)
В этом видеоуроке мы изучим один из инструментов для работы с запросами - макросы подстановок. С их помощью можно значительно увеличивать количество запросов, листать страницы и многое другое. В уроке рассмотрено:
Полезные ссылки:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!(https://www.youtube.com/c/AParser_channel)  https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ |
|
|
|
|
11.07.2019, 16:49
|
#4 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
1.2.534 - 6 новых парсеров, поддержка Node.js в tools.js, множество исправлений в парсерах(https://a-parser.com/threads/5466/)
 Улучшения
|
|
|
|
|
22.07.2019, 15:37
|
#5 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
Сборник статей #8: ссылки с GET параметрами, скачивание Google документов, очистка очереди через API(https://a-parser.com/threads/5483/)
8-й сборник статей. В нем мы научимся парсить ссылки с GET параметрами, искать в поиске Google и скачивать документы, а также узнаем как очищать очередь заданий через API. Поехали! Сбор ссылок с GET параметрами В техническую поддержку часто задают вопрос, как собирать ссылки с GET параметрами для поиска SQL уязвимостей. Поэтому, по ссылке выше мы расскажем как это сделать, используя стандартный парсер Google. 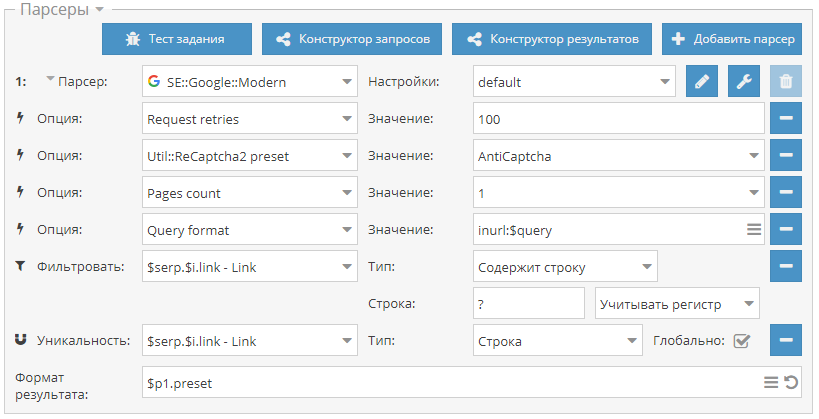 Поиск и скачивание Google документов За последнее время уже несколько раз появлялись новости о том, что Google индексирует пользовательские документы, размещенные в их одноименном сервисе и открытые для доступа по ссылке. Соответственно все эти файлы становятся доступны в поиске. И пока Google разбирается с этим, по ссылке выше мы рассказываем как можно искать и скачивать такие документы. 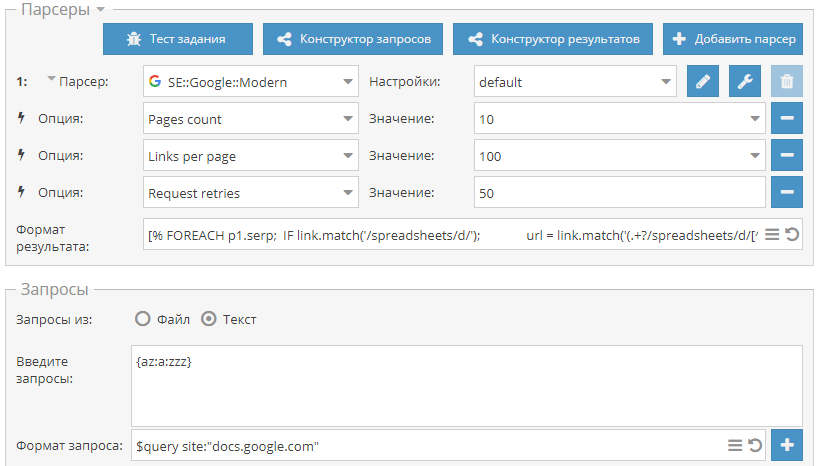 Работаем с API, часть 3 Третья и заключительная часть из цикла статей по работе с A-Parser через API. В ней на примере очистки очереди задач будет рассмотрена работа со вспомогательными запросами, которые позволяют работать с очередью заданий. Все детали - по ссылке выше.  https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ |
|
|
|
|
01.08.2019, 15:17
|
#6 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
34-й сборник рецептов, в котором опубликован пресет для оценки количества трафика на сайтах, парсер Ahrefs через API и пресет для парсинга информации об IP адресах. Поехали!
Чек трафика сайта Пресет для проверка трафика сайта через сервис siteworthtraffic.com. Собираются данные о количестве уникальных постетителей и просмотров, а также о доходе с рекламы. Оценка трафика на сайтах может быть полезна для фильтрации списка сайтов по критерию прибыльности и популярности. Пресет доступен по ссылке выше. 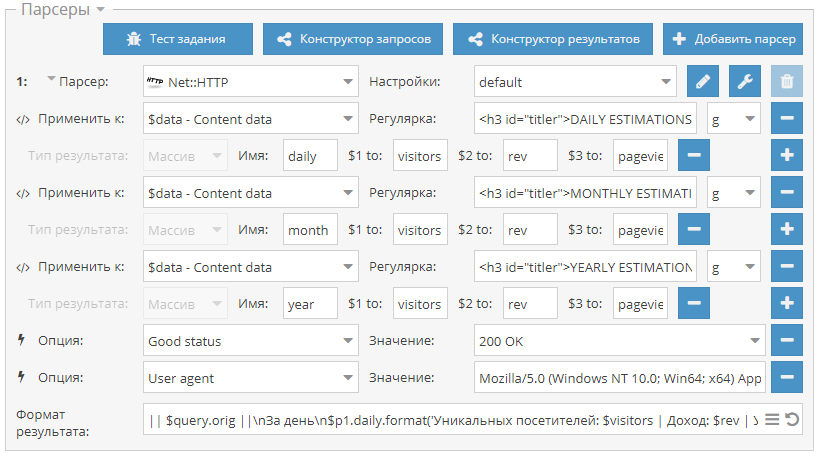 Парсер Ahrefs на основе Ahrefs API Парсер для сбора данных из популярного сервиса Ahrefs через их официальное API. Собирается множество данных, которые позволяют оценивать домены по различным характеристикам. Для использования нужен API ключ, который приобретается отдельно. 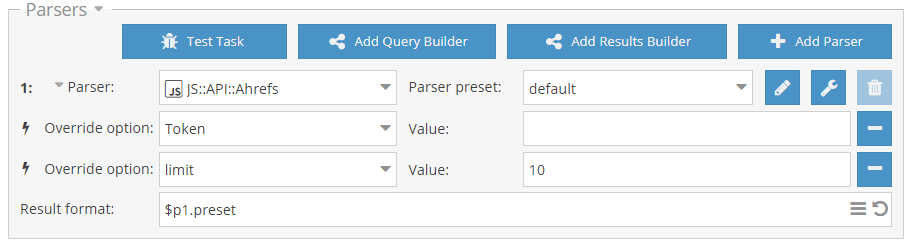 Парсинг подсети и организации по IP Небольшой пресет для сбора информации об IP адресе, а именно: подсеть, организация, страна и город. Данные собираются из сервиса whoer.net. 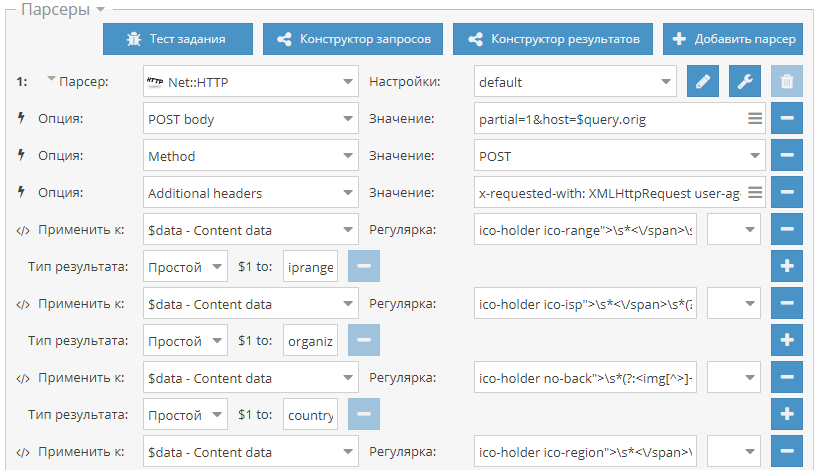 Еще больше различных рецептов в нашем Каталоге (https://a-parser.com/resources/)! Предлагайте ваши идеи для новых парсеров здесь (https://a-parser.com/threads/3464/), лучшие будут реализованы и опубликованы. Подписывайтесь на наш канал на Youtube (https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw) - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter (https://twitter.com/a_parser).  https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ |
|
|
|
|
20.08.2019, 19:08
|
#7 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
1.2.570 - новые парсеры API::Server::Redis и SE::Startpage, улучшения в существующих парсерах(https://a-parser.com/threads/5523/)
 Улучшения
 https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ |
|
|
|
|
30.08.2019, 14:47
|
#8 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
[URL=https://a-parser.com/threads/5553/]Видео урок: Поиск страниц контактов[/URL]
В этом видео уроке рассмотрен пример решения задачи по поиску страниц контактов у заданного списка сайтов. Также парсится тайтл и все это сохраняется в CSV файл. В уроке рассмотрено:
[URL=https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ] [/URL] |
|
|
|
|
09.09.2019, 16:46
|
#9 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
Сборник рецептов #35: комментарии на Youtube, контакты на сайтах и японский Yahoo(https://a-parser.com/threads/5572/])
35-й сборник результатов, где мы будем собирать комментарии из Youtube, искать контакты (телефоны и почты) на сайтах, а также парсить японскую выдачу Yahoo. Поехали! [BПарсинг комментариев из Youtube[/B] Представляем вашему вниманию JS парсер комментариев для видео на Youtube. С его помощью можно собирать тексты комментариев, а также информацию об авторах комментариев индивидуально для каждого видео. Также реализована возможность указывать количество страниц с комментарими, что позволяет при необходимости ограничить их сбор и тем самым увеличить скорость работы. 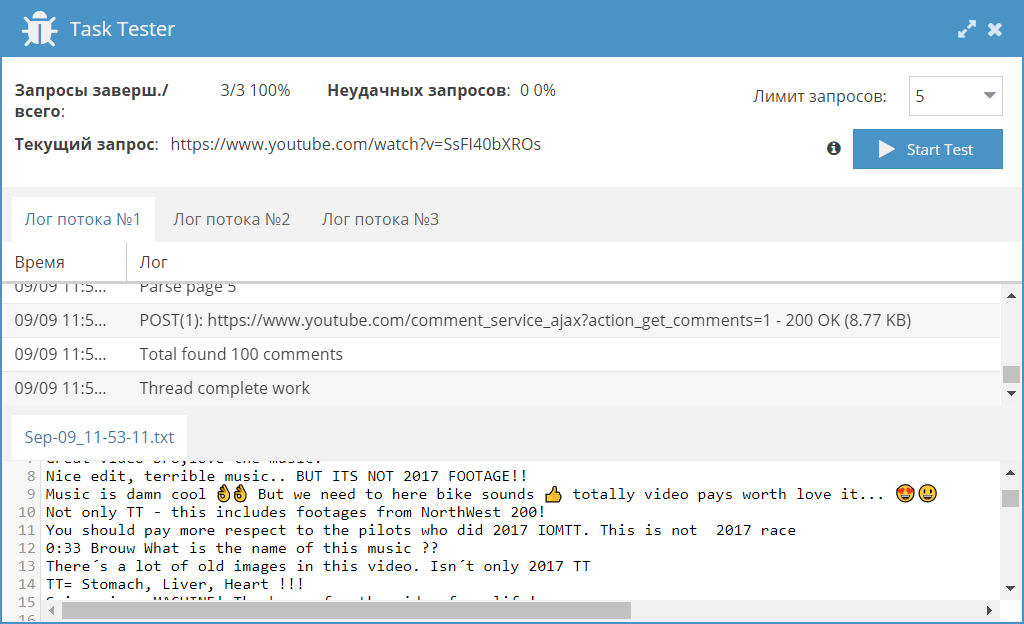 Извлекаем телефоны, начинающиеся на 3 с помощью HTML::EmailExtractor Пресет, в котором показано, как с помощью HTML::EmailExtractor HTML::EmailExtractor собирать контакты со страниц сайтов. Данный пресет предназначен для сбора e-mail и телефонов, начинающихся с 3 (Украина), но при необходимости можно немного изменить регулярные выражения и собирать телефоны других стран. 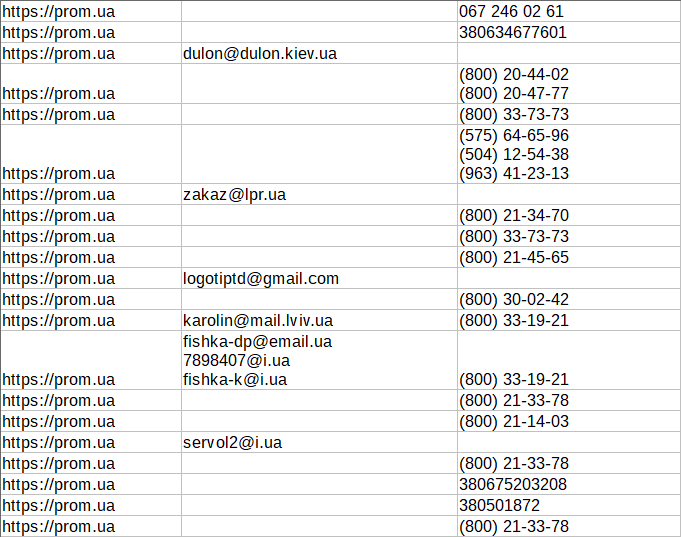 SE::Yahoo::JP JS парсер для парсинга японской выдачи Yahoo. Используется домен search.yahoo.co.jp. Собираются ссылки, анкоры и сниппеты, а также есть возможность задать количество страниц для парсинга. 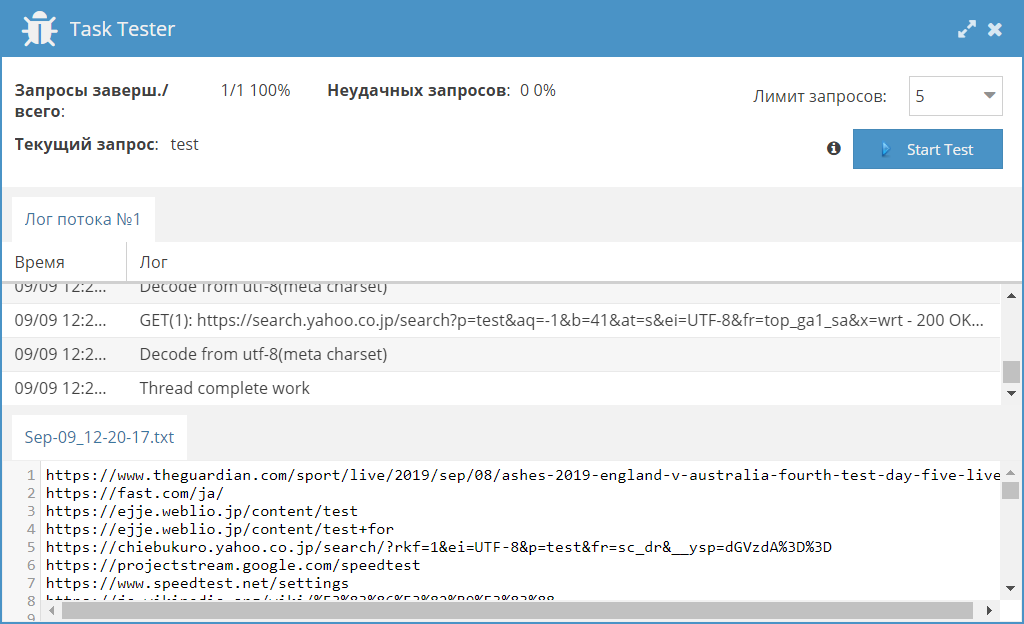 https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ |
|
|
|
|
21.09.2019, 14:54
|
#10 |
|
Пользователь
Регистрация: 01.12.2016
Сообщений: 243
Вы сказали Спасибо: 0
Поблагодарили 1 раз в 1 сообщении
Репутация: 10
|
1.2.595 - новый парсер Ahrefs, инструмент для создания CSV и много других улучшений
 Улучшения
https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ |
|
|
|


 [URL=https://a-parser.com/wiki/se-yandex/]SE::Yandex[/URL] в массив $ads добавлена переменная $visiblelink, в которой содержится видимая ссылка
[URL=https://a-parser.com/wiki/se-yandex/]SE::Yandex[/URL] в массив $ads добавлена переменная $visiblelink, в которой содержится видимая ссылка [URL=https://a-parser.com/wiki/se-yahoo/]SE::Yahoo[/URL] добавлена опция Not found is error, указывающая, считать ли отсутствие результатов ошибкой
[URL=https://a-parser.com/wiki/se-yahoo/]SE::Yahoo[/URL] добавлена опция Not found is error, указывающая, считать ли отсутствие результатов ошибкой [URL=https://a-parser.com/wiki/shop-yandex-market/]Shop::Yandex::Market[/URL]
[URL=https://a-parser.com/wiki/shop-yandex-market/]Shop::Yandex::Market[/URL] [URL=https://a-parser.com/wiki/se-google-modern/]SE::Google::Modern[/URL] исправлен парсинг видео в мобильной выдаче
[URL=https://a-parser.com/wiki/se-google-modern/]SE::Google::Modern[/URL] исправлен парсинг видео в мобильной выдаче [URL=https://a-parser.com/wiki/maps-yandex/]Maps::Yandex[/URL] исправлен парсинг рейтингов
[URL=https://a-parser.com/wiki/maps-yandex/]Maps::Yandex[/URL] исправлен парсинг рейтингов [URL=https://a-parser.com/wiki/se-duckduckgo/]SE:: DuckDuckGo[/URL],
[URL=https://a-parser.com/wiki/se-duckduckgo/]SE:: DuckDuckGo[/URL],  [URL=https://a-parser.com/wiki/shop-amazon/]Shop::Amazon[/URL],
[URL=https://a-parser.com/wiki/shop-amazon/]Shop::Amazon[/URL],  [URL=https://a-parser.com/wiki/se-baidu/]SE::Baidu [/URL]исправлена работа функции Get full links для результатов без ссылок
[URL=https://a-parser.com/wiki/se-baidu/]SE::Baidu [/URL]исправлена работа функции Get full links для результатов без ссылок Maps::Google
Maps::Google Social::Instagram::Post - парсинг данных о постах, в т.ч. комментарии и пользователей, которые лайкнули пост
Social::Instagram::Post - парсинг данных о постах, в т.ч. комментарии и пользователей, которые лайкнули пост [URL=https://a-parser.com/wiki/se-youtube/]SE::YouTube[/URL], а также исправлен сбор $title
[URL=https://a-parser.com/wiki/se-youtube/]SE::YouTube[/URL], а также исправлен сбор $title [URL=https://a-parser.com/wiki/se-google-images/]SE::Google::Images[/URL]
[URL=https://a-parser.com/wiki/se-google-images/]SE::Google::Images[/URL] [URL=https://a-parser.com/wiki/googleplay-apps/]GooglePlay::Apps[/URL]- теперь он парсит только первую страницу результатов
[URL=https://a-parser.com/wiki/googleplay-apps/]GooglePlay::Apps[/URL]- теперь он парсит только первую страницу результатов [URL=https://a-parser.com/wiki/se-seznam/]SE::Seznam[/URL] при отсутствии результатов
[URL=https://a-parser.com/wiki/se-seznam/]SE::Seznam[/URL] при отсутствии результатов [URL=https://a-parser.com/wiki/se-duckduckgo-images/]SE:: DuckDuckGo::Images[/URL],
[URL=https://a-parser.com/wiki/se-duckduckgo-images/]SE:: DuckDuckGo::Images[/URL],  [URL=https://a-parser.com/wiki/se-bing-images/]SE::Bing::Images[/URL]
[URL=https://a-parser.com/wiki/se-bing-images/]SE::Bing::Images[/URL] [URL=https://a-parser.com/wiki/net-whois/]Net::Whois[/URL]
[URL=https://a-parser.com/wiki/net-whois/]Net::Whois[/URL] [URL=https://a-parser.com/wiki/se-yandex-direct-frequency/]SE::Yandex:: Direct::Frequency[/URL]
[URL=https://a-parser.com/wiki/se-yandex-direct-frequency/]SE::Yandex:: Direct::Frequency[/URL] [URL=https://a-parser.com/wiki/html-linkextractor/]HTML::LinkExtractor [/URL]исправлен сбор ссылок, если в них есть перенос строки
[URL=https://a-parser.com/wiki/html-linkextractor/]HTML::LinkExtractor [/URL]исправлен сбор ссылок, если в них есть перенос строки Net::HTTP улучшена работа с редиректами, добавлена опция Follow common redirects
Net::HTTP улучшена работа с редиректами, добавлена опция Follow common redirects Util::ReCaptcha2 можно указать хост для используемого сервиса разгадывания, а также в Provider url можно указывать адреса через запятую (актуально для XEvil и CapMonster), парсер будет использовать каждый из них в случайном порядке
Util::ReCaptcha2 можно указать хост для используемого сервиса разгадывания, а также в Provider url можно указывать адреса через запятую (актуально для XEvil и CapMonster), парсер будет использовать каждый из них в случайном порядке SE::Rambler
SE::Rambler Social::Instagram::Profile и
Social::Instagram::Profile и  Social::Instagram::Tag изменен перечень доступных переменных в связи с не совсем корректной работой в некоторых случаях
Social::Instagram::Tag изменен перечень доступных переменных в связи с не совсем корректной работой в некоторых случаях


 Комбинированный вид
Комбинированный вид
